


Grok 4: Breaking Down xAI’s Leap
How Grok 4 became the highest-scoring AI model: Breaking down the compute power, training methods, and benchmark scores.

"With respect to academic questions, Grok 4 is better than any PhD level in any subject, no exceptions." - Elon Musk
Just over two years after Elon Musk founded xAI, the company introduced Grok 4, which they describe as the top AI model in the world.
Let's break down their announcement, starting with the massive leap in computational power.
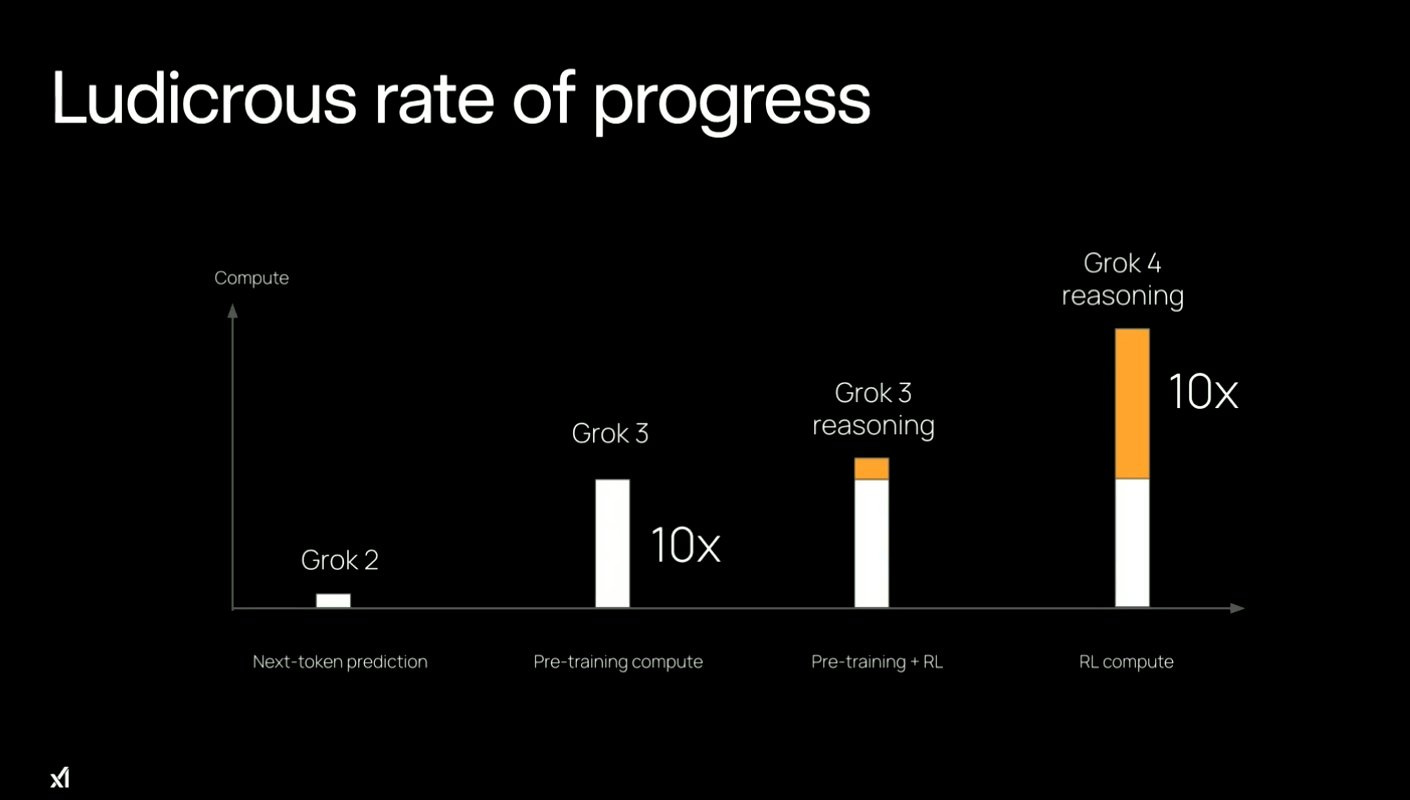
Grok 2 was a concept version. Grok 3 focused on pre-training, teaching the model new skills using multiple data sources. Grok 4 received 100x more training than Grok 2 and 10x more compute than Grok 3, staggering progress.
Grok 4 is focused heavily on Reinforcement Learning (RL) - a process where models receive questions and tasks, get graded on their results, and improve their responses accordingly. This approach is known to make models significantly smarter, especially at logical problem-solving.
Thinking from first principles, they figured that focusing on RL would give them the most advancement in the shortest time. Their results suggest they succeeded.
AGI Scoring Breakthrough
One of the most impressive achievements for Grok 4 is its ARC-AGI score of 15.9%, significantly higher than any other model on the market according to xAI's evaluation.
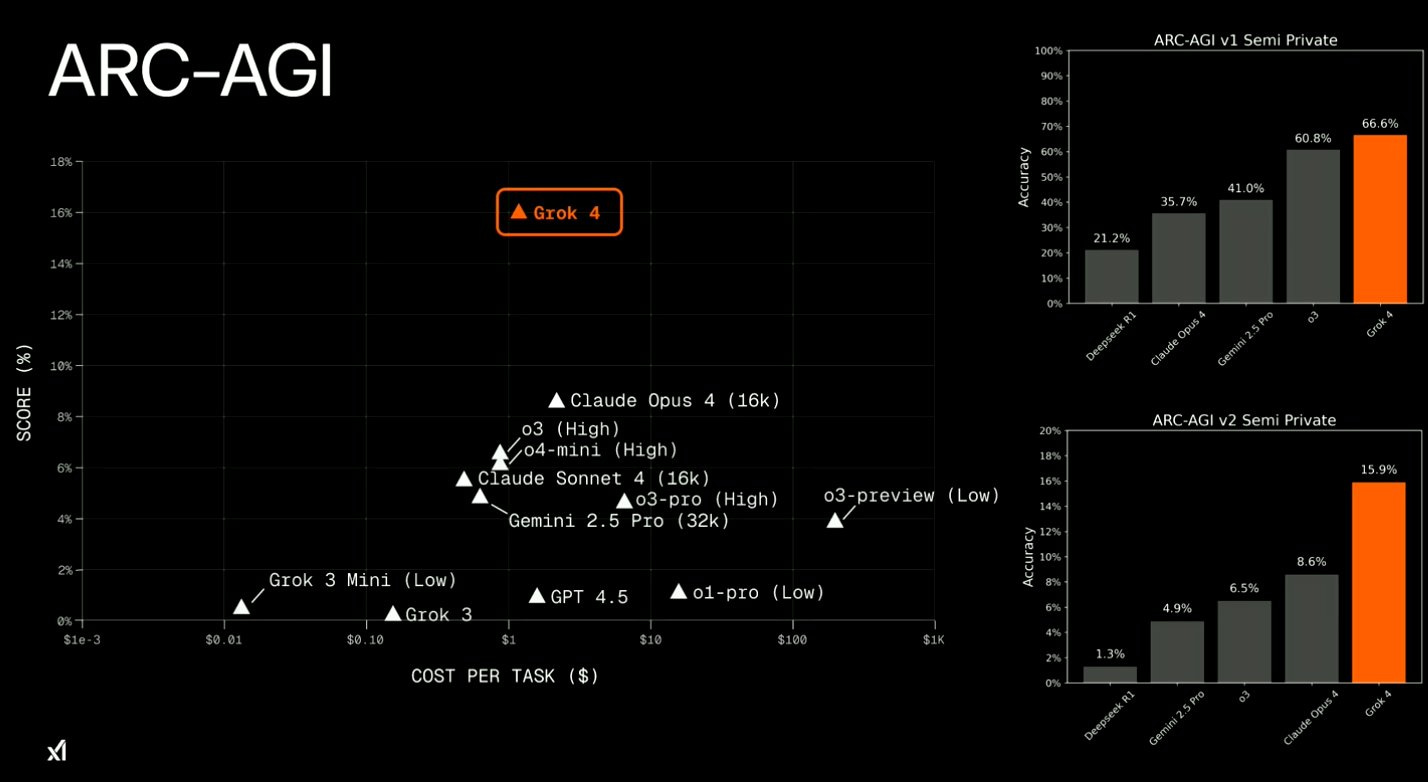
The ARC-AGI test measures a model's ability to solve novel, abstract reasoning tasks with minimal prior exposure. It's designed to measure general intelligence rather than specialized skills through visual puzzles where models must identify patterns and apply them to new scenarios - essentially mimicking human-like problem-solving.
Humanity's Last Exam
The Humanity's Last Exam (HLE) is a new benchmark released in January 2025 that xAI calls "a very, very challenging benchmark." It consists of approximately 2,500 expert-crafted questions across over 100 disciplines such as math, biology, social science, physics, AI, engineering, chemistry, and others.

Grok 4 delivered impressive results:
Without tools: 26.9%
With tools (Grok 4 Heavy): 41%
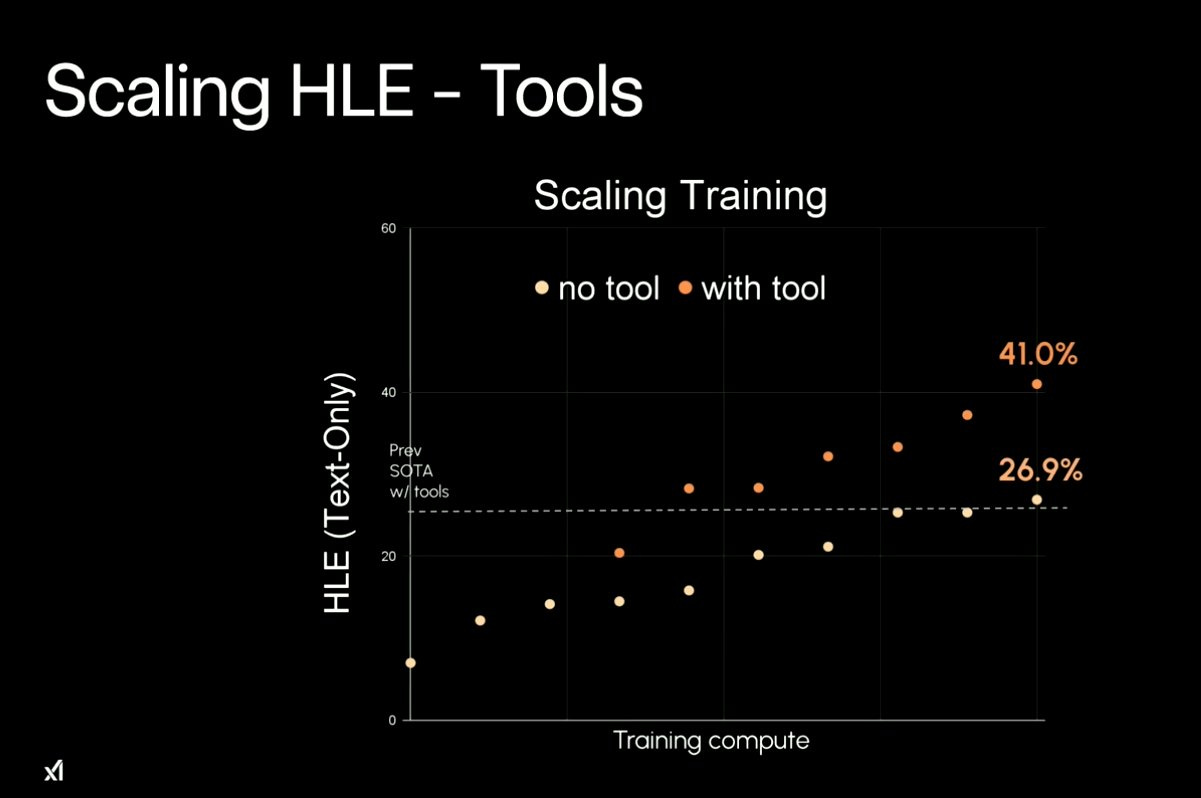
The distinction between these scoring methods is good to understand:
No Tools means Grok 4 operates solely on its internal capabilities, relying on pre-trained knowledge and reasoning without external aids. It tackles problems using only its inherent language and reasoning abilities.
With Tools refers to Grok 4 Heavy, which uses a multi-agent system and external tools like code execution, web search, and data retrieval.
Here's where it gets interesting. xAI suggest Grok 4 Heavy achieved up to 50.7% on HLE with enhanced test-time compute.
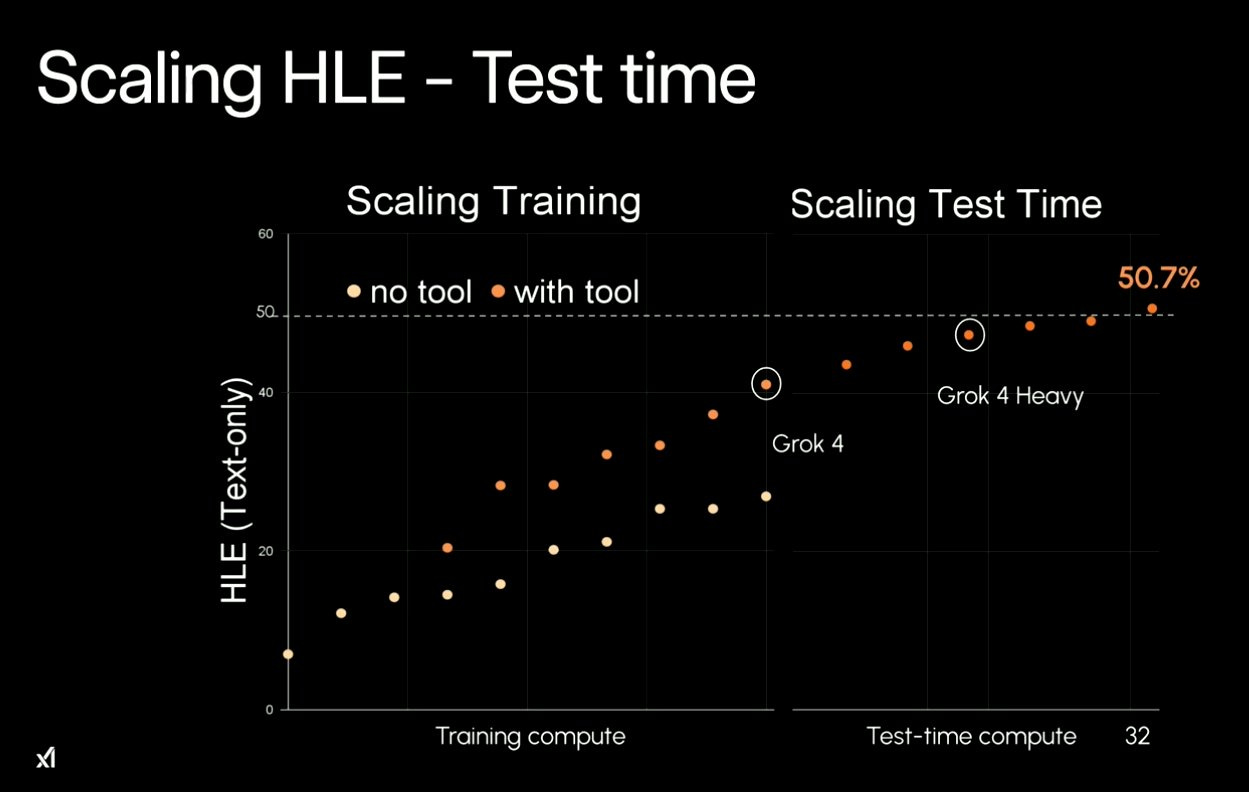
To explain:
Training Compute is the computing power used to create and train Grok 4 Heavy on xAI's Colossus supercomputer (200,000 GPUs). This builds the model's foundational knowledge and tool-use capabilities.
Test-Time Compute is the computing power used when answering questions during testing. It runs multiple copies of the model in a team-like system, using tools and checking each other's work. This extra effort can take 32x longer but potentially boosts performance significantly.
Dominating the Benchmarks
Grok 4's performance is impressive across various “typical“ AI benchmarks.
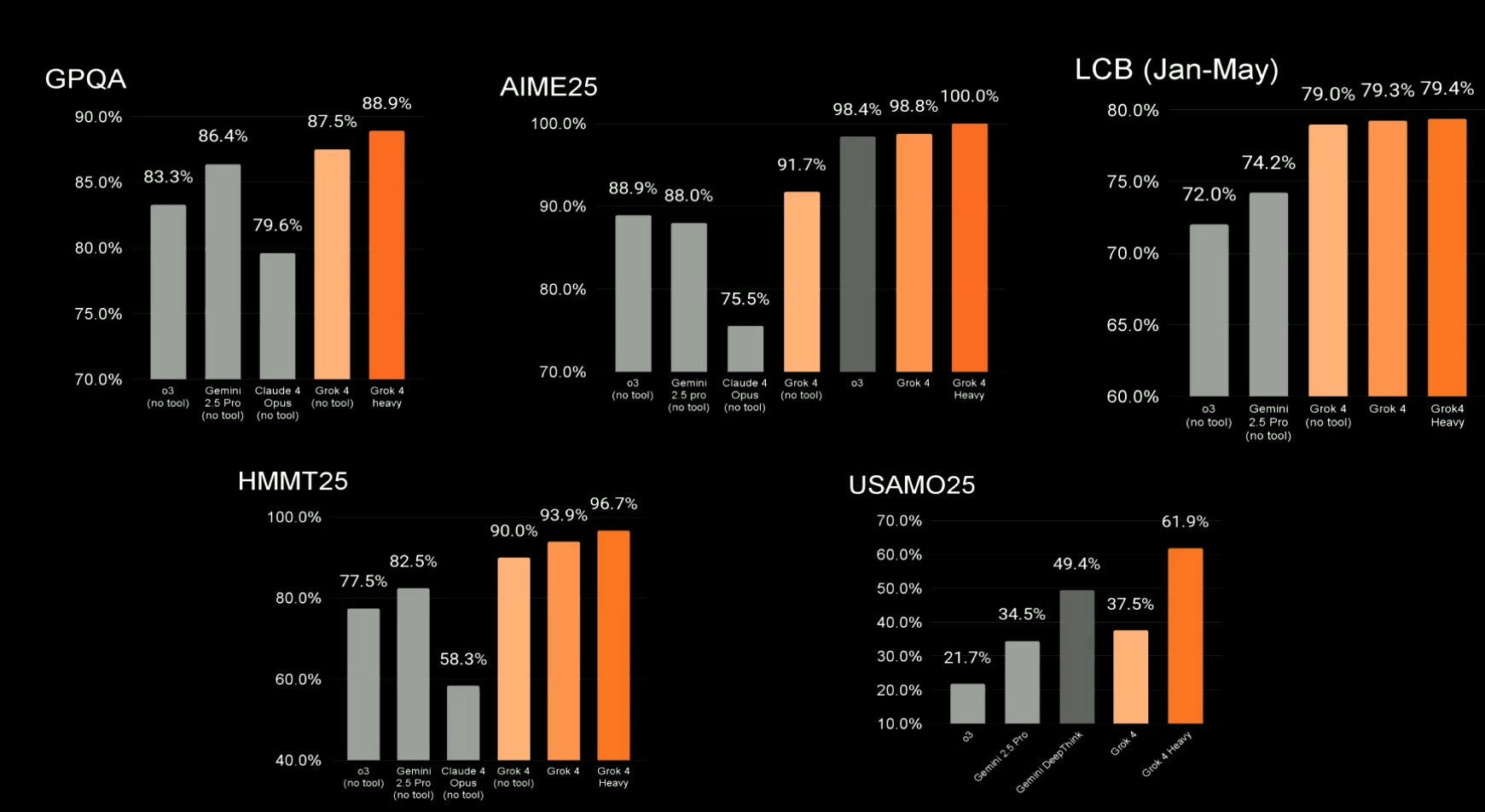
To explain these scores:
AIME: Tests complex high school math problems in algebra and geometry
GPQA: Measures graduate-level science reasoning in physics and other fields
LiveCodeBench: Evaluates coding skills through Python programming challenges
MMLU-Pro: Tests knowledge across professional subjects with challenging multiple-choice questions
LOFT: Assesses ability to extract information from long texts for complex queries
Native Voice Revolution
Beyond intelligence, Grok 4 introduces a new native voice mode that enables fluid, real-time conversations. The AI can be interrupted naturally, understands and replicates emotional tones, and responds with very low latency, creating a far more human-like interaction than previous text-to-speech systems.
What's Next?
xAI's roadmap is aggressive:
August: Coding model release
September: Multimodal agent
October: Video-generating model
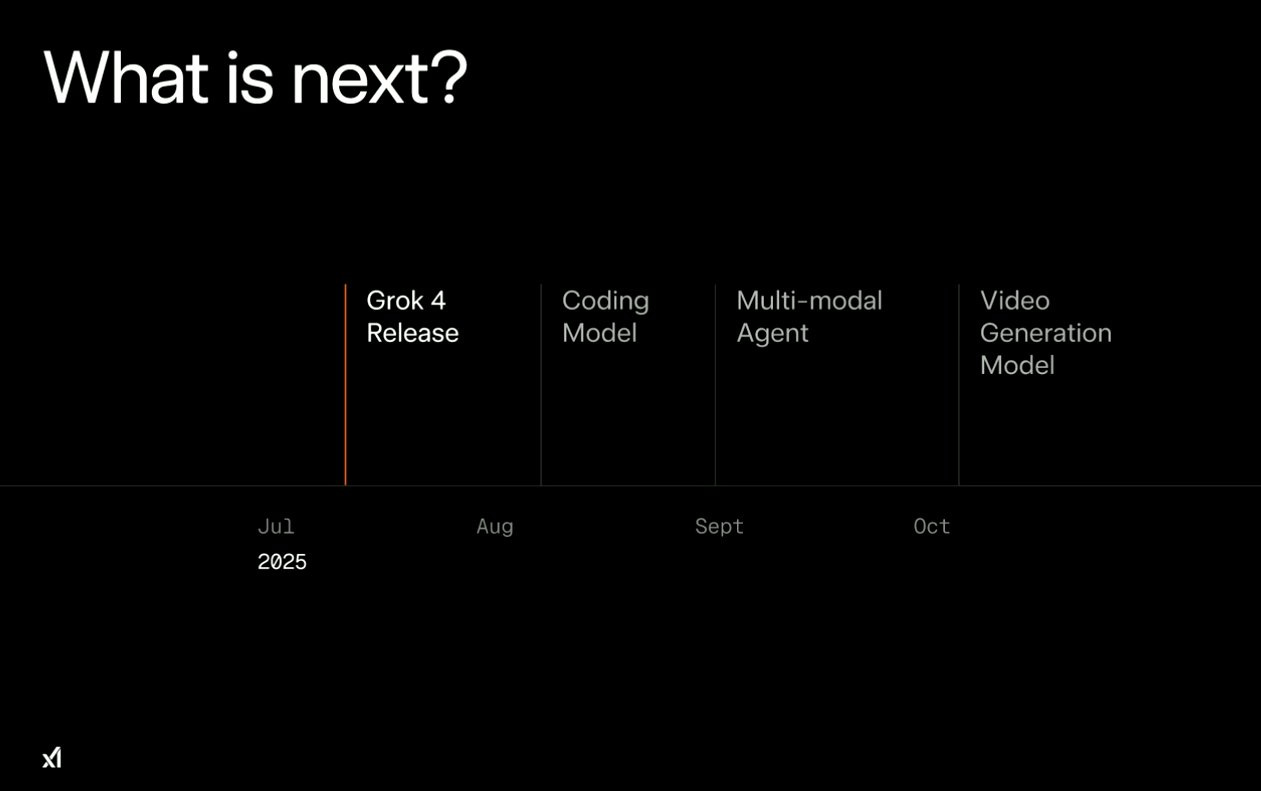
In other words, Grok will continue to improve their tooling going forward.
Bottom Line
Grok 4 represents a significant step forward in AI capability, particularly in reasoning and academic problem-solving. The benchmark results suggest it's genuinely competitive with or superior to current leading models from OpenAI and Google. Whether this translates to practical advantages in real-world applications remains to be seen, but the technical achievement is noteworthy.
The rapid development timeline from xAI - going from zero to potentially leading AI model in under two and a half years - is perhaps as impressive as the technology itself. It demonstrates that the AI race is far from over and players keep hitting the gas.